Blogs

.jpeg)
Questions to ask before planning the app modernization
According to the Market Research Future report, the application modernization services market is expected to reach USD 24.8 billion by 2030, growing at a CAGR of 16.8%. Nobel technologies and improved applications are two driving factors of this growing market size. On one side, it is growing, and on another side, it is failing also. According to this report, unclear project expectations are the biggest reason behind its failure.
That’s why app modernization is a big decision for your organization and business expansion. To avoid failure, you must prepare a list of good questions before planning the app’s modernization. Read the full article to understand a brief of app modernization, its need cum benefits, and questions which could help in designing the best app modernization strategy.
What is App modernization?
App modernization replaces or updates existing software, applications, or IT infrastructure with new applications, platforms, or frameworks. It is like an application upgrade on a period to utilize the technology trends and innovation. The primary purpose of app modernization is to improve the current legacy systems’ efficiency, security, and performance. The process encompasses not only updating or replacing but also reengineering the entire infrastructure.
Need/Benefits of App modernization
Application modernization is growing across industries. It meant it became an essential business need. Here are points which are highlighting that why you need the app modernization for your business:
- To improve the business performance
- To scale the IT infrastructure to work globally
- To increase the security and protection of expensive IT assets
- To enhance the efficiency of business processes and operations
- To reduce the costs which happen due to the incompatibility of older systems with newer technologies
10 Questions need to consider before planning the app modernization
Before designing the add modernization strategy, you need a list of questions according to your business objective and services. Here are questions that might help you to make a proper plan for app modernization:
1. What is the age of your existing legacy business applications?
You have to understand your existing IT infrastructure and resources. How it is working and performing in the current environment. Are they creating problems or running smoothly? Are they causing downtime often? If they are too old, you need to replace everything; although if you upgrade them regularly, check which resource needs to modernize.
2. What are the organization’s current technical skills and resources?
You have to analyze the existing team and experts and understand whether they can adapt to the new infrastructure. You have to know their capabilities regarding learning new applications. In case you did modernization without analyzing your existing team’s capability, but after some time, you find that your experts are facing issues while working on the new IT environment. Thus, knowing the current technical skills and how you would train them for the transformation is good.
3. Would you be willing to conduct a Proof Of Concept (POV) to verify the platform’s functionality?
Are new system features able to solve the problems, and are they beneficial for business? You need to perform POV to check the new system’s functionality and find out how it works. POV can help you to examine the essential features and other characteristics of modernized apps.
4. Can the new system be easily modified to meet the business’s and customers’ changing needs?
Business needs and customer demands are not static. You know it, and it changes as soon as technological advancement or regulatory changes happen. It would be best if you found out that an application would be able to adopt the changes to fulfill your business requirements.
5. How have you surveyed the market and decided on the appropriate platform(s) to execute essential modernization?
You must research the market and list all vendors offering the services you seek for your application modernization. Analyze all factors before finalizing the best platform and services aligned with your objective.
6. How secure are the applications currently?
You have to find the security level of your legacy applications. Because modern apps need high levels and advanced security systems. Old security practices on modern apps might fail your project, so better to check the existing security.
7. Assess the opportunity costs and business risks associated with avoiding modernization?
If you avoid the app modernization, how many business opportunities might you lose, or how many risks might you face? If you escape them, you might face many losses. As discussed, modernization is a business priority in this futuristic technology era. So, be sure to understand its importance on time and execute it as soon as possible.
8. What type of modernization are you seeking?
You need to know the flexibility of your decision regarding app modernization. In simple words, which kind of modernization are you looking for in your business progress? Are you looking for a permanent or a system that could be altered in some years?
9. Did you consider the cloud when designing your application?
Running applications and managing the whole IT infrastructure on the cloud is a business priority. If your legacy applications are not compatible with the cloud, you must understand how you can make them cloud compatible. By doing this, you can easily migrate and modernize your applications to the cloud.
10. Determine what integrations are required to modernize the app?
With modernized applications, you must know the required integrations among hardware, software, or other IT assets. This answer will help you locate the best and ideal platform for your business process execution.
Forbes Councils Member Yasin Altaf has pointed out four factors – evaluate technical and business challenges, assess the current state of the legacy system, find out the right approach, and plan in his recent article. Besides being the leading voice in emerging enterprise technology, Infoworld has also revealed that time and proper tools are key drivers of the app modernization success in this report. In addition, giving time to develop and plan is the best way, according to 36% of IT leaders.
Thus, along with these questions, you must consider factors like time, budget, risk factors, and management constraints before planning the modern app.
Closing Thought
You research, ask questions from various resources, and analyze everything before purchasing anything!
Why?
To get the exemplary product/service!
It applies to app modernisation too. Your business needs modernized applications in the modern technology era. A questionnaire will help you plan an appropriate app modernization if you want the right service and execution. We hope the questions we have provided can help you find answers to all your questions. Interested in modernizing your legacy applications? Contact us. You can always count on our expert team for assistance.
.jpeg)
Cloud-based disaster recovery strategies for your businesses
Did you know the disaster recovery solution market is projected to reach USD 115.36 Billion by 2030, growing at a CAGR of 34.5%, according to this research report conducted by market intelligence company, StraitsResearch?
What do you think is causing it to rise?
Because disasters can strike anywhere and anytime, regardless of their type (natural, artificial, or technical failures). Experiencing losses due to unexpected disasters can be challenging for your business. That’s why most organizations, from SMEs to large corporations, are considering developing a cloud-based IT Disaster Recovery Plan to ensure their business runs smoothly in the event of a catastrophe. Rather than turning to traditional disaster recovery methods, these businesses prefer to use cloud-based solutions. Many market players offer cloud-based disaster recovery strategies, but AWS cloud is one of the top cloud service platforms. Because it provides various disaster recovery strategy options for small to large business organizations, you can select strategies according to your business industry, requirements, and budget.
In this article, you will get information about disaster recovery plans & strategies, and checklists available on the AWS cloud.
Why do you need cloud-based disaster recovery strategies?
Disaster recovery refers to the process of preparing and recovering from a disaster. You must always be ready to manage unplanned adverse events to run your business smoothly. That’s why you need to plan, strategies, and test cloud-based disaster recovery strategies. Cloud-based disaster recovery strategies provide solutions implemented in the cloud with the help of a specific cloud service provider. Read below 3 points to know its importance more precisely:
- You can save your security budget by investing in an entire disaster recovery site and paying as per use.
- You can access and recover any on-premises and cloud-based software and applications in case of a disaster in seconds from the cloud.
- You can minimize downtime and data loss along with on-time recovery.
These reasons would help you to know the rising demands of cloud-based disaster recovery strategies among business industries.
Develop a Disaster Recovery Plan (DRP)
Implementation of any strategy requires a plan and checklist. You must also make a disaster recovery plan and tick mark the essential checklist to implement any cloud-based disaster cloud strategy. Generally, this plan must be part of a Business Continuity Plan (BCP), which ensures business continuity during and after disasters.
The following 3 tasks will make things easy for you regarding adopting the cloud-based DRP.
Task 1: Know your infrastructure
Your first job is to understand your existing IT environment and assess the data, assets, and other resources. You must know everything, like where data has been stored, the cost of these data, and possible risks. Evaluation of the risks and threats can help you understand the possible types of disasters that might happen.
Task 2: Conduct a business impact analysis and risk assessment
Your next job is to do business impact analysis to measure the business impacts of disruptions to your workloads. Simply put, find out the business operations constraints once disaster strikes. Additionally, do a risk assessment to learn the possibility of disaster occurrence and its geographical impact by understanding the technical infrastructure of the workloads. Don’t forget to consider these two essential factors:
- Recovery Time Objective (RTO) – It refers to the maximum time (acceptable delay), an application can stay offline after the disaster to its recovery.
- Recovery Point Objective (RPO) – It refers to the maximum time (adequate time) for which you can bear data loss from your application. In other words, find the lost time between service interruption and the last recovery point.
Look at the below image to understand these factors more easily:

Image credit: Amazon AWS
Task 3: Know your workloads to implement disaster recovery in the cloud
Implementing disaster recovery on on-premise is different from implementing it in the cloud. To execute cloud-based disaster recovery effectively, you need to analyze your workloads. You must check your data centre connectivity if you have already deployed the workload on the cloud.
But, deploying your workloads on the AWS cloud would benefit disaster recovery implementation. AWS will take of everything from data center connectivity to providing fault-isolated Availability Zones ( an area to support physical redundancy), and regions.
- Go for a single AWS Region if you have high workloads, as you will get different availability zones.
- Go for multiple AWS Regions if there is a possibility of losing various data centers far from each other.
Disaster recovery strategy options in AWS Cloud
The rising popularity of AWS is happening because of more than 20 AWS services available for disaster recovery. But every business has its objective, background, and technical infrastructure. Thus, you should know all options. AWS Cloud offers four major approaches for disaster recovery, shown in the following image:

Image: Disaster Recovery Approaches
Let’s understand each approach and all available AWS services within each approach.
(1) Backup & Restore
Backup & Restore is a common approach for disaster recovery. Check the following table to learn more about it:
What it does
- Mitigate data loss and corrupted data
- Replicate data to AWS regions
- Mitigate lack of redundancy for workload deployed to a single Availability Zone
What you need to consider
- Use Infrastructure as code (IaC) for deployment, and for this, consider AWS CloudFormation or AWS Cloud Development Kit.
- Develop a Backup strategy using AWS Backup
- Create Amazon Ec2 instances using Amazon Machine Images
- Automate redeployment using AWS CodePipeline
Available AWS Services
- Amazon Elastic Block Store (Amazon EBS) Snapshot
- Amazon DynomoDB backup
- Amazon RDS snapshot
- Amazon EFS backup
- Amazon Redshift snapshot
- Amazon Neptune snapshot
- Amazon DocumentDB
Check the following image to understand the backup and restore architecture on the AWS cloud.

Image: Backup and restore architecture
(2) Pilot Light
Pilot light is a second approach for disaster recovery through replication (continuous, cross-region, asynchronous). Check the following table to learn more about it:
What it does
- Helps you to replicate data from one Region to another region
- Allows you to work on your core infrastructure and quickly provision a full-scale production environment through scaling servers and switching on
What you need to consider
- Automate IaC and deployments to deploy core infrastructure at one place and across multiple accounts and Regions
- Use different accounts per Region to offer the highest level of security isolation and resources
Available AWS Services
- Amazon Simple Storage Service (S3) Replication
- Amazon Aurora global database
- Amazon RDS read replicas
- Amazon DynamoDB global tables
- Amazon DocumentDB global clusters
- Global Datastore for Amazon ElastiCache for Redis
- AWS Elastic Disaster Recovery
- For Traffic Management
- Amazon Route 53
- AWS Global Accelerator
Check the following image to understand the Pilot Light architecture on the AWS cloud.

Image: Pilot Light architecture
(3) Warm Standby
The warm Standby approach focuses on scaling. Check the following table to learn more about it:
What it does
- Ensure the scaling and fully functional copy of the production environment in another Region
- Offers quick and continuous testing
What you need to consider
- Scaleup everything which needs to be deployed and running
- Since it is similar to the Pilot Light approach, consider factors, RTO & RPO for selecting one from these.
Available AWS Services
- You can use all AWS services mentioned in the above two approaches for data backup, data replication, infrastructure deployment, and traffic management.
- Use AWS Auto Scaling for scaling resources
Check the following image to understand the Warm Standby architecture on the AWS cloud.

Image: Warm Standby architecture
(4) Multi-site active/active
Multi-site active/active approach offers disaster recovery in multiple regions. Check the following table to learn more about it:
What it does
- Helps you to recover data in various regions
- Reduce recovery time but also offer a complex and expensive approach
What you need to consider
- Don’t forget to test the disaster recovery to know how the workload responds to the loss of a Region
- You need to work more on maintaining security and avoiding human errors
Available AWS Services
- Like Warmup Standby, you can use all AWS services mentioned in the above three approaches for data backup, data replication, infrastructure deployment, and traffic management.
Check the following image to understand the Multi-site active/active architecture on the AWS cloud.

Image: Multi-site active/active architecture
How to choose a suitable strategy
It would be best if you made the right decision by selecting the appropriate strategy according to the business requirements. Still, consider the following points and check to decide the best one:
Points to consider
- AWS divides services into two categories – the data plane to offer real-time services and the control plane to configure the environment. It is suggested that you should go with data plane services to get maximum resiliency.
- Choose the Backup & Restore strategy options if you need only backup of workloads and restorage with the single physical data center. Besides this requirement, you can choose from rest 3 strategies.
- The first 3 approaches are active/passive strategies which use an active site like AWS Region for hosting and serving and a passive site (another AWS Region) for recovery.
- Regular testing and updating of your disaster recovery strategies are vital. You can take the help of AWS Resilience Hub to track your AWS workload.
- Use AWS Health Dashboard to get up-to-date information about the AWS service status. It provides a summary like the below image:

Image: Dummy data on AWS Health Dashboard
Tick-make this checklist for your DRP and strategies implementation
Here is a checklist that can help you to effectively design, develop, and implement disaster recovery plans and strategies. Consider it like a questionnaire for successful implementation:
Have you figured out recovery objective (RTO / RPO)?Have to found the stakeholder lists which needs to update once disaster strike?Have you established the essential communication channels during and after disaster events?Have you collected all business operations and IT infrastructure documents?Have you defined any procedure to manage incidents or actions?Have you performed testing of your strategies? Use AWS Config for monitoring the configurations.Does your documentation are up-to-date?
Case study – How Thomson Reuters got benefits after implementing AWS cloud-based disaster recovery approach
In 2020, Thomson Reuter, a Global news and information provider, depended on the traditional Disaster recovery process, which was time-consuming and expensive. The company realized the need for modern cloud-based disaster recovery to improve data security and recover applications for one of its business units. They connected with Amazon AWS and AWS partner Capgemini and decided to implement AWS Elastic Disaster Recovery to minimize data loss, downtime, fast recovery, and on-premises recovery. In 10 months, the company implemented this strategy on 300 servers. The automation of the cloud-based DR process provided them with the following outcomes:
- Replicated over 120 TB of data from 300 servers
- Setup a recovery site in the cloud
- Eliminate its manual DR process
- Optimized spending on its DR process
- Enhanced security and data protection
See the below image to understand how AWS Elastic Disaster Recovery works. It is visible that it follows the simple process of recovering and replicating any data. In this case, the company also leveraged this work, but before that, they built an AWS Landing Zone to set up a secure and multi-account AWS environment to meet the security requirements. Afterward, they set up a recovery site in the cloud using the AWS Elastic Disaster Recovery service. This new solution has started offering continuous data replication at minimum costs.

Image: Working of AWS Elastic Disaster Recovery
Closing Thought
AWS cloud is not only used by this company but by many other companies as well for disaster recovery. With AWS cloud disaster recovery, you can make a quick recovery with minimal complexity, lower management overheads, and simple or repeatable testing. Analyze your requirements, and decide what disaster recovery strategy is best for you. With the right decisions, you can get these benefits for your business’s growth and smooth operation
.jpeg)
Cloudtech Achieves the AWS Service Delivery Designation for AWS Lambda
About bNoteable
bNoteable helps you showcase your hard work on a path to reach your goals by leveraging your band, orchestra, or vocal experience to its fullest potential to college admissions boards.
This begins early by setting a course that allows you to turn those hours of fun and friendship into leadership experience, hours of practice and performances into scholarship potential, and years of music classes into overall higher SATs and GPA scores, and academic achievement.
Executive Summary
Continuing the development of a musician networking platform which involved implementing new features, enhancing the existing ones, and fixing bugs/errors/issues in the platform by improving its efficiency and productivity along with making the platform responsive.
Problem Statement
Our client wanted us to design and create a social platform where each and every user is able to connect and interact with one another easily. He came to us after a bad experience with some other company and was expecting to continue the development by improving website performance as well as efficiency.
The platform had various bugs which needed to be fixed and some major features were to be added like payment service, OTP service, adding more security along with improving existing features. Performance of platform was being affected as there were some major issues like:
1. Deployment architecture- Everything was deployed on a single EC2 instance due to which there was a high amount of downtime. The performance was impacted more when the user base was increased.
2. The videos on his platform were taking a lot of time to load.
Our Solutions
1) We followed MVC architecture for developing REST API using express as middleware and mongoose for managing data in MongoDB. Authenticated API with jwt by using JSON web token package.
2) Added payment service in the platform by integrating stripe payment gateway with help of stripe package, created OTPs for security/validation which was communicated via SMS with help of Twilio.
3) To improve the performance, we deployed the backend on a separate ec2 instance with Nginx as reverse proxy and pm2 as process manager which comes with a built-in load balancer and helps to keep the application alive forever.
4) Installed Nginx on the server, and changed the Nginx.conf file configurations as per the requirement and it worked as a load balancing solution. Also replaced the lets encrypt SSL certificates with ACM(AWS Certificate Manager) to make certificate renewal, provision, and management process better as well as easy.
5) For adding new features to the platform, the frontend involved creating several components, services, directives, pipes, and modules in Angular.
6) To reduce the load time we implemented Lazy loading with help of Lazy load routes. The reason behind increased load time for videos was the use of video tag over secured protocol, to solve this we used iframe for rendering videos which proved to be much faster.
7) Changed the existing deployment architecture and moved the front-end to S3 so that load on the server can be reduced. We moved the front-end to S3 with CloudFront as CDN for speeding up the distribution of web content and improving performance.
Technologies
Angular 10, Node, Express, MongoDB, AWS S3, EC2, CloudFront
Success Metrics
1. Provided all the deliverables within the expected deadlines, improved performance as down time reduced and videos were no longer buffering for a long time.
2. Met all the expectations of the client and with positive feedback. All his meetings with directors and students were successful due to which he wanted us to implement some more new features on his platform.
3. Continuous reporting of progress to the client.
‚Äç

Highlighting Serverless Smarts at re:Invent 2023
Quiz-Takers Return Again and Again to Prove Their Serverless Knowledge
This past November, the Cloudtech team attended AWS re:Invent, the premier AWS customer event held in Las Vegas every year. Along with meeting customers and connecting with AWS teams, Cloudtech also sponsored the event with a booth at the re:Invent expo.
With a goal of engaging our re:Invent booth visitors and educating them on our mission to solve data problems with serverless technologies, we created our Serverless Smarts quiz. The quiz, powered by AWS, asked users to answer five questions about AWS serverless technologies, and scored quiz-takers based on accuracy and speed at which they answered the questions. Paired with a claw machine to award quiz-takers with a chance to win prizes, we saw increased interest in our booth from technical attendees ranging from CTOs to DevOps engineers.
But how did we do it? Read more below to see how we developed the quiz, the data we gathered, and key takeaways we’ll build on for re:Invent next year.
What We Built
Designed by our Principal Cloud Solutions Architect, the Serverless Smarts quiz was populated with 250 questions with four possible answers each, ranging in difficulty to assess the quiz-taker’s knowledge of AWS serverless technologies and related solutions. When a user would take the quiz, they would be presented with five questions from the database randomly, given 30 seconds to answer each, and the speed and accuracy of their answers would determine their overall score. This quiz was built in a way that could be adjusted in real-time, meaning we could react to customer feedback and outcomes if the quiz was too difficult or we weren’t seeing enough variance on the leaderboard. Our goal was to continually make improvements to give the quiz-taker the best experience possible.
The quiz application's architecture leveraged serverless technologies for efficiency and scalability. The backend consisted of AWS Lambda functions, orchestrated behind an API Gateway and further secured by CloudFront. The frontend utilized static web pages hosted on S3, also behind CloudFront. DynamoDB served as the serverless database, enabling real-time updates to the leaderboard through WebSocket APIs triggered by DynamoDB streams. The deployment was streamlined using the SAM template.
Please see the Quiz Architecture below:

What We Saw in the Data
As soon as re:Invent wrapped, we dived right into the data to extract insights. Our findings are summarized below:
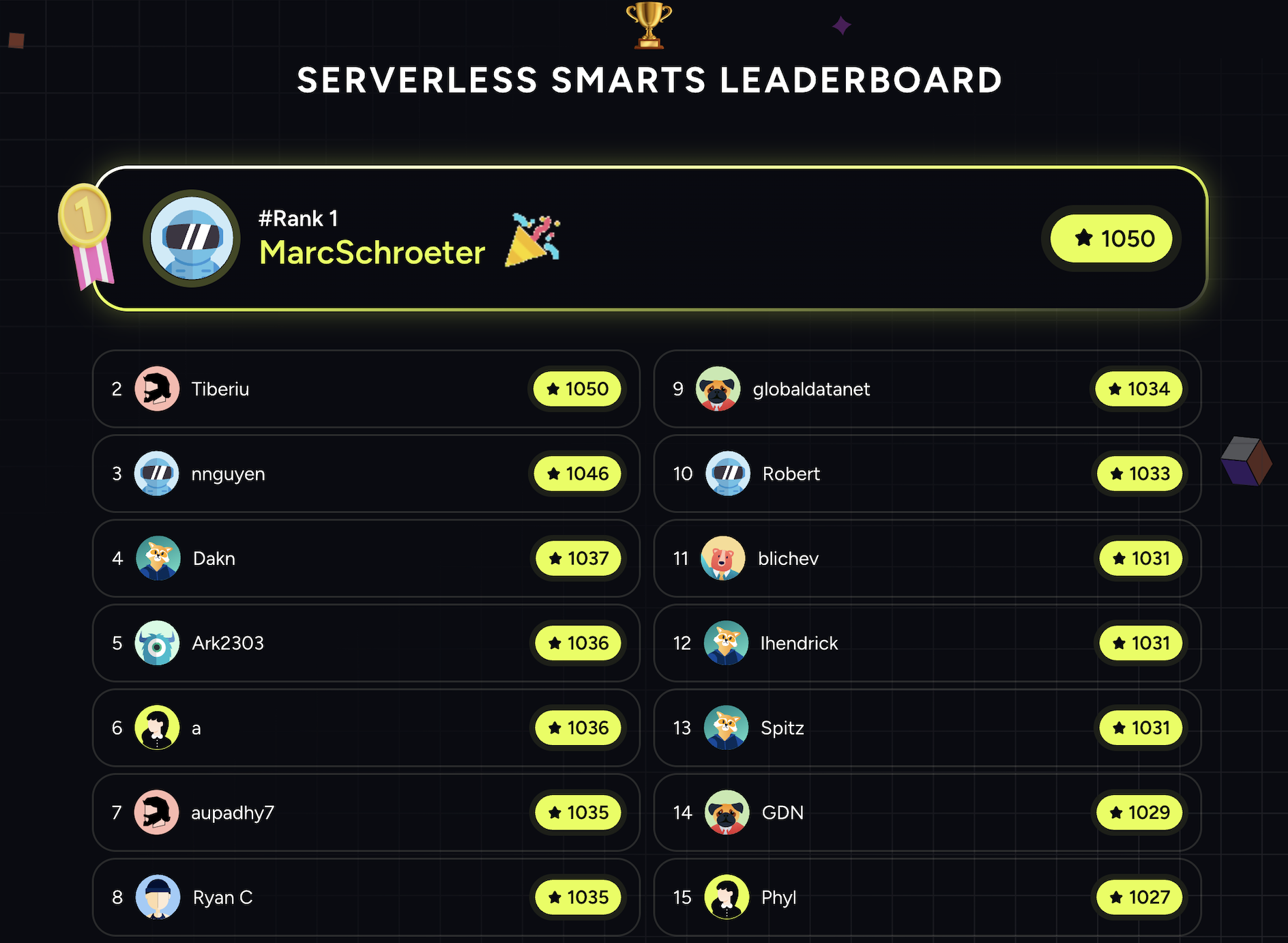
- Quiz and Quiz Again: The quiz was popular with repeat quiz-takers! With a total number of 1,298 unique quiz-takers and 3,627 quizzes completed, we saw an average of 2.75 quiz completions per user. Quiz-takers were intent on beating their score and showing up on the leaderboard, and we often had people at our booth taking the quiz multiple times in one day to try to out-do their past scores. It was so fun to cheer them on throughout the week.
- Everyone's a Winner: Serverless experts battled it out on the leaderboard. After just one day, our leaderboard was full of scores over 1,000, with the highest score at the end of the week being 1,050. We saw an average quiz score of 610, higher than the required 600 score to receive our Serverless Smarts credential badge. And even though we had a handful of quiz-takers score 0, everyone who took the quiz got to play our claw machine, so it was a win all around!
- Speed Matters: We saw quiz-takers soar above the pressure of answering our quiz questions quickly, knowing answers were scored on speed as well as accuracy. The average amount of time it took to complete the quiz was 1-2 minutes. We saw this time speed up as quiz-takers were working hard and fast to make it to the leaderboard, too.
- AWS Proved their Serverless Chops: As leaders in serverless computing and data management, AWS team members showed up in a big way. We had 118 people from AWS take our quiz, with an average score of 636 - 26 points above the average - truly showcasing their knowledge and expertise for their customers.
- We Made A Lot of New Friends: We had quiz-takers representing 794 businesses and organizations - a truly wide-ranging activity connecting with so many re:Invent attendees. Deloitte and IBM showed the most participation outside of AWS - I sure hope you all went back home and compared scores to showcase who reigns serverless supreme in your organizations!
Please see our Serverless Smarts Leaderboard below
What We Learned
Over the course of re:Invent, and our four days at our booth in the expo hall, our team gathered a variety of learnings. We proved (to ourselves) that we can create engaging and fun applications to give customers an experience they want to take with them.
We also learned that challenging our technology team to work together and injecting some fun and creativity into their building process combined with the power of AWS serverless products can deliver results for our customers.
Finally, we learned the value of thinking outside the box to deliver for customers is the key to long term success.
Conclusion
re:Invent 2023 was a success, not only in connecting directly with AWS customers, but also in learning how others in the industry are leveraging serverless technologies. All of this information helps Cloudtech solidify its approach as an exclusive AWS Partner and serverless implementation provider.
If you want to hear more about how Cloudtech helps businesses solve data problems with AWS serverless technologies, please connect with us - we would love to talk with you!
And we can’t wait until re:Invent 2024. See you there!

Enhancing Image Search with the Vector Engine for Amazon OpenSearch Serverless and Amazon Rekognition
Introduction
In today's fast-paced, high-tech landscape, the way businesses handle the discovery and utilization of their digital media assets can have a huge impact on their advertising, e-commerce, and content creation. The importance and demand for intelligent and accurate digital media asset searches is essential and has fueled businesses to be more innovative in how those assets are stored and searched, to meet the needs of their customers. Addressing both customers’ needs, and overall business needs of efficient asset search can be met by leveraging cloud computing and the cutting-edge prowess of artificial intelligence (AI) technologies.
Use Case Scenario
Now, let's dive right into a real-life scenario. An asset management company has an extensive library of digital image assets. Currently, their clients have no easy way to search for images based on embedded objects and content in the images. The company’s main objective is to provide an intelligent and accurate retrieval solution which will allow their clients to search based on embedded objects and content. So, to satisfy this objective, we introduce a formidable duo: the vector engine for Amazon OpenSearch Serverless, along with Amazon Rekognition. The combined strengths of Amazon Rekognition and OpenSearch Serverless will provide intelligent and accurate digital image search capabilities that will meet the company’s objective.
Architecture
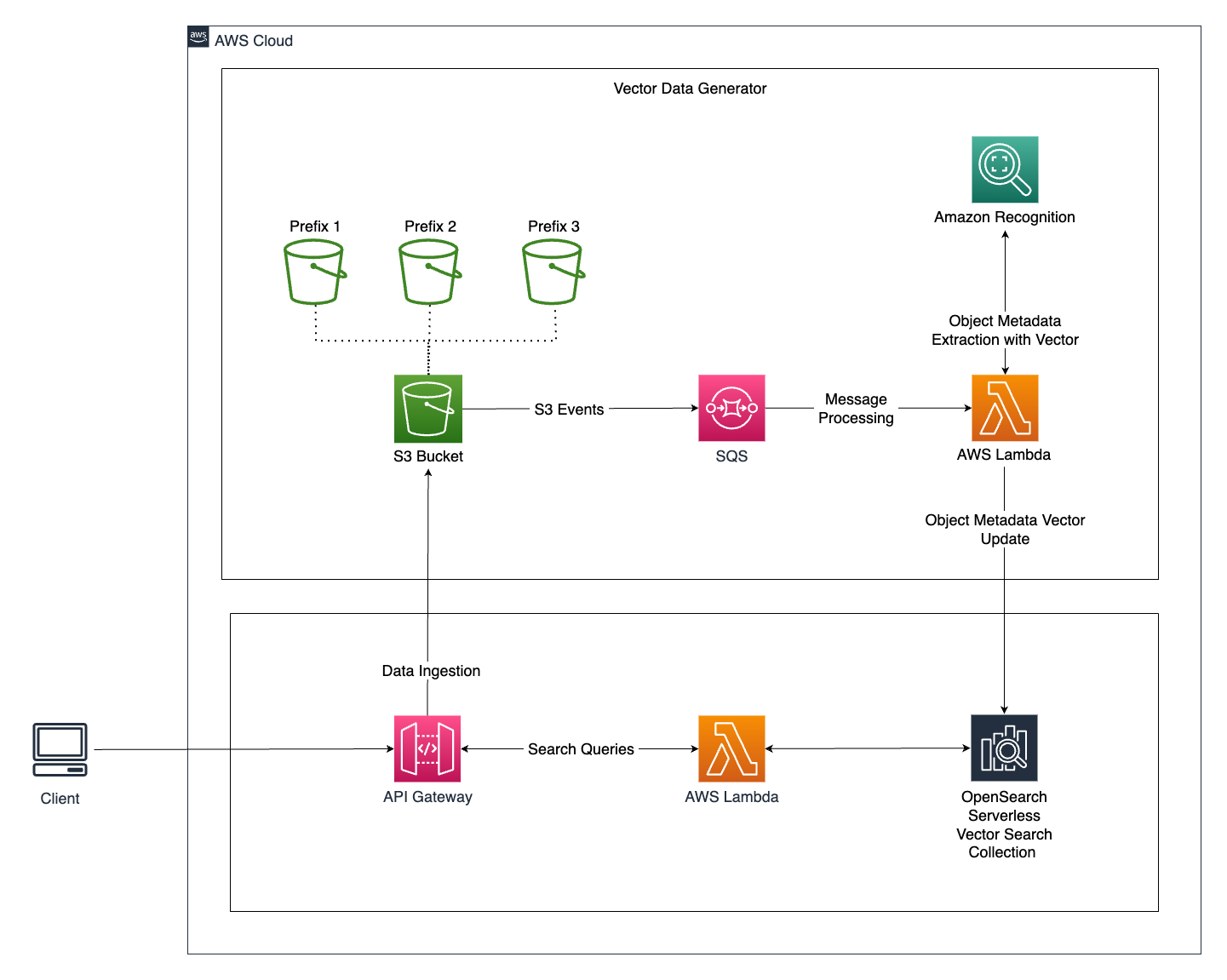
Architecture Overview
The architecture for this intelligent image search system consists of several key components that work together to deliver a smooth and responsive user experience. Let's take a closer look:
Vector engine for Amazon OpenSearch Serverless:
- The vector engine for OpenSearch Serverless serves as the core component for vector data storage and retrieval, allowing for highly efficient and scalable search operations.
Vector Data Generation:
- When a user uploads a new image to the application, the image is stored in an Amazon S3 Bucket.
- S3 event notifications are used to send events to an SQS Queue, which acts as a message processing system.
- The SQS Queue triggers a Lambda Function, which handles further processing. This approach ensures system resilience during traffic spikes by moderating the traffic to the Lambda function.
- The Lambda Function performs the following operations:
- Extracts metadata from images using Amazon Rekognition's `detect_labels` API call.
- Creates vector embeddings for the labels extracted from the image.
- Stores the vector data embeddings into the OpenSearch Vector Search Collection in a serverless manner.
- Labels are identified and marked as tags, which are then assigned to .jpeg formatted images.
Query the Search Engine:
- Users search for digital images within the application by specifying query parameters.
- The application queries the OpenSearch Vector Search Collection with these parameters.
- The Lambda Function then performs the search operation within the OpenSearch Vector Search Collection, retrieving images based on the entities used as metadata.
Advantages of Using the Vector Engine for Amazon OpenSearch Serverless
The choice to utilize the OpenSearch Vector Search Collection as a vector database for this use case offers significant advantages:
- Usability: Amazon OpenSearch Service provides a user-friendly experience, making it easier to set up and manage the vector search system.
- Scalability: The serverless architecture allows the system to scale automatically based on demand. This means that during high-traffic periods, the system can seamlessly handle increased loads without manual intervention.
- Availability: The managed AI/ML services provided by AWS ensure high availability, reducing the risk of service interruptions.
- Interoperability: OpenSearch's search features enhance the overall search experience by providing flexible query capabilities.
- Security: Leveraging AWS services ensures robust security protocols, helping protect sensitive data.
- Operational Efficiency: The serverless approach eliminates the need for manual provisioning, configuration, and tuning of clusters, streamlining operations.
- Flexible Pricing: The pay-as-you-go pricing model is cost-effective, as you only pay for the resources you consume, making it an economical choice for businesses.
Conclusion
The combined strengths of the vector engine for Amazon OpenSearch Serverless and Amazon Rekognition mark a new era of efficiency, cost-effectiveness, and heightened user satisfaction in intelligent and accurate digital media asset searches. This solution equips businesses with the tools to explore new possibilities, establishing itself as a vital asset for industries reliant on robust image management systems.
The benefits of this solution have been measured in these key areas:
- First, search efficiency has seen a remarkable 60% improvement. This translates into significantly enhanced user experiences, with clients and staff gaining swift and accurate access to the right images.
- Furthermore, the automated image metadata generation feature has slashed manual tagging efforts by a staggering 75%, resulting in substantial cost savings and freeing up valuable human resources. This not only guarantees data identification accuracy but also fosters consistency in asset management.
- In addition, the solution’s scalability has led to a 40% reduction in infrastructure costs. The serverless architecture permits cost-effective, on-demand scaling without the need for hefty hardware investments.
In summary, the fusion of the vector engine for Amazon OpenSearch Serverless and Amazon Rekognition for intelligent and accurate digital image search capabilities has proven to be a game-changer for businesses, especially for businesses seeking to leverage this type of solution to streamline and improve the utilization of their image repository for advertising, e-commerce, and content creation.
If you’re looking to modernize your cloud journey with AWS, and want to learn more about the serverless capabilities of Amazon OpenSearch Service, the vector engine, and other technologies, please contact us.

Cloudtech's Approach to People-Centric Data Modernization for Mid-Market Leaders
Engineering leaders at mid-market organizations are facing a significant challenge: managing complex data systems while juggling rapid growth and outdated technologies. Many of these organizations left their former on-premises ecosystems for greener pastures in the cloud without fully understanding the impact of this change. This shift has created issues from higher-than-expected cloud costs to engineers who are unprepared to turn over control to cloud providers. These new challenges are not only highly technical but also deeply human, affecting teams and processes at every level. Cloudtech understands these challenges and addresses them with a unique approach combining a people-centric focus paired with an iterative delivery mechanism ensuring transparency throughout the entire engagement.
Embracing a People-Centric Approach
At the heart of Cloudtech's philosophy is a simple truth: technology should serve people, not the other way around. This people-centric approach begins with a deep understanding of the needs, challenges, and capabilities of your team. Based on our findings, we are able to create customized solutions to fit your organization’s data infrastructure modernization goals. By focusing on this human aspect, Cloudtech ensures that our solutions don't just solve technical problems but also support and empower the people who spend their lives ensuring organizations have the right technology solutions to grow and support business needs.
Iterative, Tangible Improvements
Our “base hits” approach terminology comes from baseball, where base hits, though seemingly small, lead to significant victories. Cloudtech adopts a similar philosophy when we engage with our customers. This base hits approach is about consistent, manageable progress that accumulates over time. For your team, this means a sense of continuous achievement and motivation, allowing you to measure progress at every stage.
A Different Kind of Company
At Cloudtech, we are redefining the essence of professional services in the cloud industry. Our foundation is built on the expertise of engineering leaders who intimately understand the pressures of the role. Our mission is to assist mid-market companies to get the most out of their data, helping them centralize and modernize their data infrastructure to improve decision making and prepare them for a Generative AI future. We accomplish this by leveraging AWS serverless solutions to help our customers improve operational efficiency, reduce infrastructure management and lower their cloud costs.
Ready to get the most out of your data?
Discover how our unique delivery approach can streamline your processes, lower your cloud costs and help you feel confident about the current and future state of your organization’s technology.
Take the first step to modernizing your data infrastructure.
Schedule a Consultation | Learn More About Our Solutions